Book Notes: Hands On Large Language Models: Language Understanding and Generation
Overview
This post contains my notes on the book *Hands-On Large Language Models: Language Understanding and Generation.
You can find the book on Amazon
I’ll be adding my notes to this post as I read through the book. The notes will be organized by chapter and will include key concepts, code examples, and any additional insights I find useful.
Chapter 1: An Introduction to Large Language Models
Chapter 1 introduces the reader to the recent history of Large Language Models (LLMs). The diagrams in this chapter are particularly useful for understanding the evolution of LLMs and how they relate to other AI technologies. It’s a great segway from the machine learning and neural networks covered in the previous book I’m reading in parallel.
Chapter 2: Tokens and Embeddings
Chapter 2 introduces the concept of tokens and embeddings.
Tokens are the basic units of text that LLMs use to process and generate language. The chapter covers a number of LLM Tokenizers including BERT (cased and uncased), GPD-2, FLAN-T5, StarCoder2, and a few others. It provides details on how each tokenizer works and how they differ from one another.
Token embeddings are numerical representations of tokens that capture their semantic meaning. Embeddings can be used to represent sentences, paragraphs, or even entire documents. Further, embeddings can be used in Recommendation Systems. The chapter covers a song recommendation system that uses embeddings to recommend songs based on a song input by the user.
Chapter 3: Looking Inside Large Language Models
Note: This chapter contains a number of useful diagrams that I’ve described in my own representation. However, the diagrams are not reproduced in their entirety. Please refer to the book for the complete diagrams and explanations.
Chapter 3 takes a deeper dive into the architecture of LLMs. We start out with a view into the Inputs and Outputs of Trained Transformer LLMs. This might be an overly simplified view, but it helps to understand the basic flow of data through an LLM.
The transformer generates a single output token at a time, using the previous tokens as context. This is known as an autoregressive model.
Diving a little deeper, we learn about the Transformer architecture. It’s composed of a Tokenizer, a stack of Transformer blocks, and an LM Head.
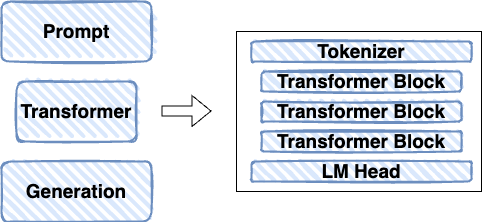
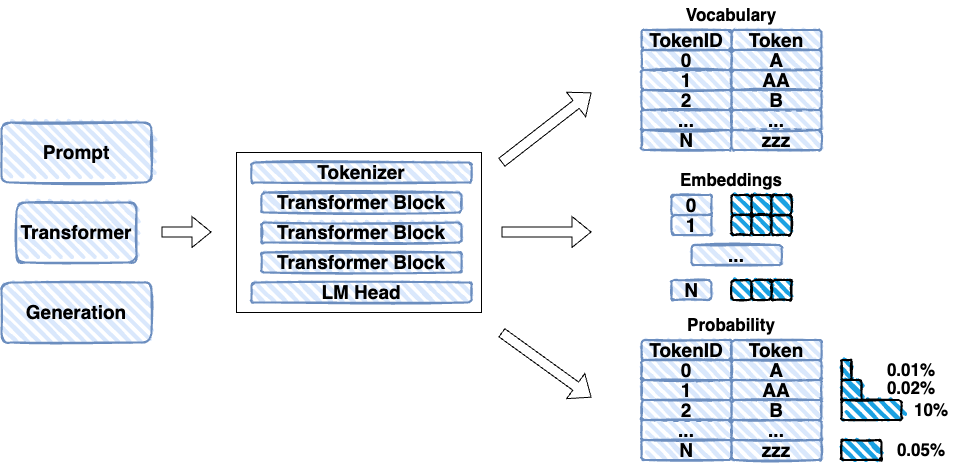
Going further, the tokenizer breaks down the input text into tokens and becomes a token vocabulary. The set of transformer blocks have token embeddings based on the token vocabulary. The LM head is a neural network layer that contains token probabilities for each token in the vocabulary.
Greedy decoding is when the model selects the token with the highest probability at each step.
It is possible to process in parallel multiple input tokens and the amount of tokens that can be processed at once is referred to as the context size. Keep in mind that embeddings are not the same as tokens, but rather a numerical representation of tokens that captures their semantic meaning.
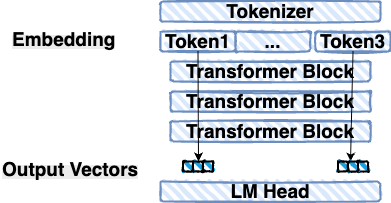
Keep in mind that only the last token in the sequence is used to generate the next token. Even though this is the case, the processing stream results are parallelized and can be cashed to improve efficiency.
Digging even deeper, we learn about the Transformer blocks. Each block consists of a self-attention mechanism and a feed-forward neural network.
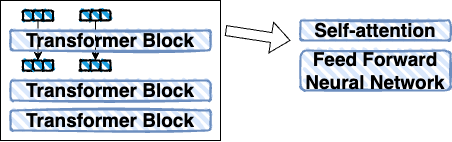
The feed-forward neural network is the source of learned information that enables the model to generate coherent text.
Attention is a key mechanism in LLMs that allows the model to focus on specific parts of the input sequence when generating text.
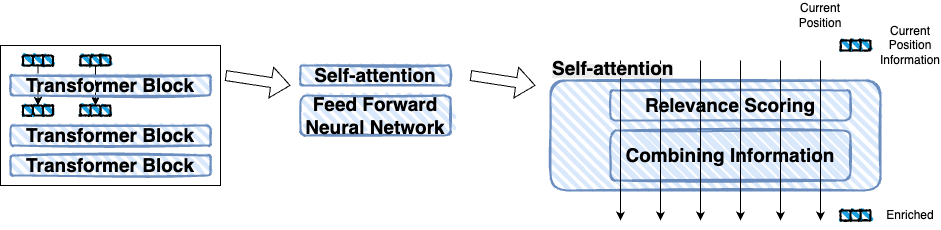
Taking a look into attention more closely, we see that we are getting to the core of how LLMs work.
Note: The book mentions projection matrices which are shown in the diagram below. However, it doesn’t explain them in detail. If you’re interested in understanding projection matrices, a good resource that I found helpful is this article. The content appears to be a summarization of the original paper on self-attention, Attention Is All You Need. Another good resource is The Illustrated Transformer
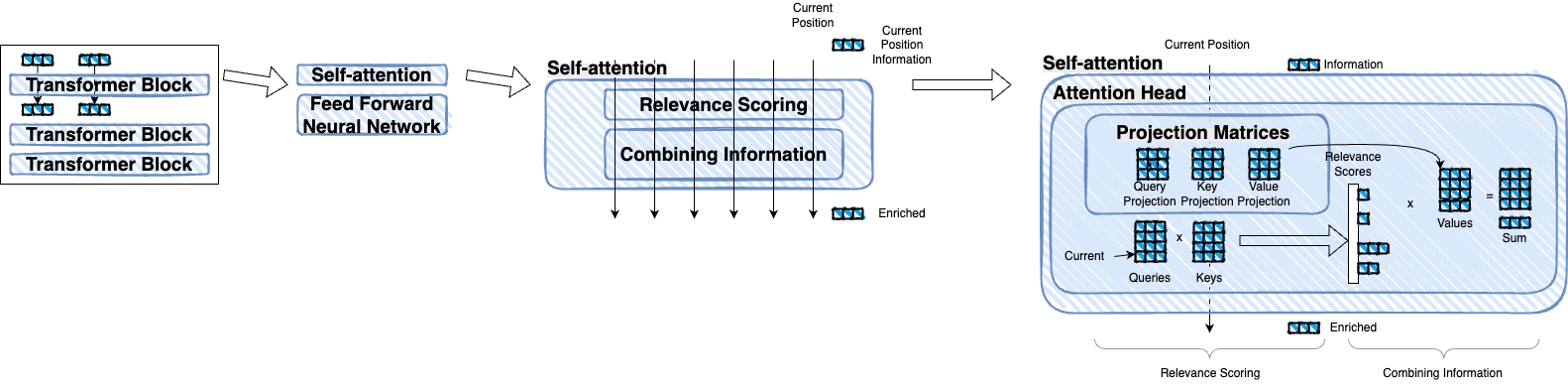
Using the queries and keys, the model calculates relevance scores for each token in the input sequence. The scores are then multiplied by the values to produce the output vectors.
Attention is a powerful mechanism that allows the model to weigh the importance of different tokens in the input sequence when generating text. Newer LLMs have available a more efficient attention mechanism called sparse attention, which can be strided or fixed. These attention mechanisms use fewer input tokens as context for self-attention.
Additionally, there are other attention mechanisms such as:
- Grouped Query Attention (GQA)
- Multi-Head Attention
- Flash Attention
Chapter 4: Text Classification
The goal of text classification is to assign a label to a piece of text based on its content. Classification can be used for a variety of tasks, such as:
- sentiment analysis
- topic classification
- spam detection
- intent detection
- detecting language
Techniques:
- Text Classification with Representation Models
- Text Classification with Generative Models
Text Classification with Representation Models
How it works:
- Based models are fine-tuned for specific tasks, like classification or embeddings.
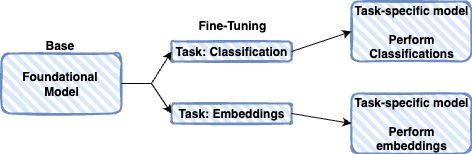
- The models are fed inputs and outputs specific to the task are generated.
There are some suggestions for models that are good for text classification:
- BERT base model (uncased)
- RoBERTa base model
- DistilBERT base model (uncased)
- DeBERTa base model
- bert-tiny
- ALBERT base v2
When looking to generate embeddings the MTEB Leaderboard is a good resource to find models.
To evaluate the performance of classification models that have labeled data, we can use metrics such as accuracy, precision, recall, and F1 score.
Zero-shot classification is a technique that allows us to classify text without any labeled data.
Using the cosine similarity function, we can compare the embeddings of the input text to the embeddings of the labels.
Text Classification with Generative Models
Prompt engineering is the process of designing prompts that can effectively elicit the desired response from a generative model.
The T5 model is similar to the original Transformer architecture, using an encoder-decoder structure.
OpenAI’s GPT model training process is published here: https://openai.com/index/chatgpt/
Chapter 5: Text Clustering and Topic Modeling
Text clustering is the process of grouping similar pieces of text together based on their content, yeilding clusters of symantically similar text.
Text clustering can be used for topic modeling, which is the process of identifying the main topics in a collection of text.
The book example uses ArXiv papers as the text corpus.
Common Pipeline for Text Clustering:
- convert input documents -> embeddings w/ embedding model
- Reduce dimensionality w/ dimensionality reduction model
- find groups of documents w/ cluster model
Dimensionality Reduction
There are well known method for dimensionality reduction including:
- Principal Component Analysis (PCA)
- Uniform Manifold Approximation and Projection (UMAP)
Clustering Algorithms
An example of clustering algorithms include:
- Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN)
Visualization of clusters can be done using tools like Matplotlib.
BERTopic: Modular Topic Modeling Framework
- Follow the same procedure in text clustering to generate clusters
- Model distribution over words, bag of words - use frequency of words in each cluster to identify topics
- Use class-based term frequency inverse document frequency (c-TF-IDF) to identify words that are unique to each cluster
A full pipeline for topic modeling using BERTopic:
| clustering | topic representation | reranking |
|---|---|---|
| sbert -> umap -> hdbscan | count vectorizaton -> c-TF-IDF | reprentation model |
| embed docs -> reduce dim -> cluster docs | tokenize words -> weight words | fine tune representation |
BERTopics can be used like Legos to build custom pipelines.
Chapter 6: Prompt Engineering
Basics of using text generation model
- Select a model considering:
- opensource vs proprietary
- output control
- Choose opensource or proprietary model
suggestion: start with a small foundational model
Load the model
Control the output
- set do_Sample=True to use temperature and top_p
- Tune Temperature and top_p for the use case
Intro to prompt engineering
Ingredients of a good prompt:
- When no instructions are given, the model will try to predict the next word based on the input text.
- Two components of basic instructions:
- Task description
- Input text (data)
- Extending the prompt with output indicator allows for specific output
Use cases for instruction based prompts:
- Supervised classification
- Search
- Summarization
- Code generation
- Named entity recognition
Techniques for improving prompts:
- Specificity
- Hallucination mitigation
- Order
Complex prompt components:
- Persona
- Instruction
- Context
- Format
- Audience
- Tone
- Data
In-context learning:
- Zero-shot learning
- One-shot learning
- Few-shot learning
Chain prompting:
- Break the task into smaller sub-tasks and use the output of one prompt as the input to the next prompt.
- Useful for:
- Response validation
- Parallel prompts
- Writing stories
Reasoning with Generative Models
Chain of thought:
- Prompt the model to think step-by-step
Self-consistency:
- using the same prompt multiple times to generate multiple responses
- works best with temperature and top_p sampling
Tree of thought:
- useful when needing to explore multiple paths to a solution
- ask the model to mimic multiple agents working together to solve a problem
- question each other until they reach a consensus
Output Verification
- Useful for:
- Structured output
- Valid output
- ethics
- accuracy
Techniques:
- Provide examples of valid output
Grammar: constrained sampling
- use packages for:
- Guidance
- Guardrails
- LMQL
Chapter 7: Advanced Text Generation Techniques and Tools
LangChain is a framework for using LLMs which has modular components. Phi-3 is an implementation of LangChain.
Quantization reduces the number of bits used to represent parameters of an LLM while retaining most of its information. It reduces precision of value without removing vital information.
A basic form of LongChain is a single chain.
Example: PromptTemplate -> LLM -> Output
More complex chains can have multiple inputs and outputs.
Example: Input -> PromptTemplate1 -> LLM1 -> Output1 -> PromptTemplate2 -> LLM2 -> Output2
The book uses a template chain to desmonstrate how to write a story using multiple prompts.
Example: Title -> Character -> Story
Limitation: LLMs don’t have memory of previous interactions.
To address this limitation, we can use a memory component to summarize previous interactions and then include the summary in the prompt for the next interaction.
Agents
Agents are systems that use an LLM to determine which actions to take based on the input and the current state of the system.
Agests use step by step reasoning:
- thought
- action
- observation
Chapter 8: Semantic Search and Retrieval-Augmented Generation
The book covers three broad categories for how langage models can be used for search:
- Dense Retrieval
- Reranking
- Retrieval-Augmented Generation (RAG)
Dense Retrieval
Using embeddings to represent documents and queries in a vector space.
Drawbacks
- Texts don’t have an answer => use threshild level for maximum distance to return an answer
- Exact match => use hybrid search (semantic + keyword)
- Corpus other than what the model was trained on => use domain-specific model
- limited context size => one vector per document or chunk documents
Options for chunking
- each sentence
- paragraph
- include title in chunk
- add text before and after chunk
Use vector database to store and search embeddings.
Reranking
Reranking can be used to improve the results of a search by using a more powerful model to rerank the results of a simpler model.
How Reranking works:
- Query and Search results are passed to a reranking model
- Reranking model scores each result based on relevance to the query
- Results are sorted based on the scores
Effectively this is a classification problem where the model returns a value between 0 and 1 for each result.
Retrieval Evaluation Metrics
Evaluation metrics for retrieval models include:
- text archive
- set of queries
- relevance judgements
To compare two search systems, use the same query set and relevance judgements for both systems.
- score only relevant documents
relevant docs (position 1) / (position 1)
- continue for each relevant doc
- average the scores for each query
Calculate Mean average precision (MAP) for each system and compare the results.
mean average precision (MAP) is the mean of the average precision scores for each query.
RAG: Retrieval-Augmented Generation
RAG systems reduce hallucinations and improve factuality.
Basic RAG Pipeline: Question -> Retriever -> Grounded Generation -> answer
Advanced RAG Techniques:
- Query Rewriting
- Multi-query RAG
- Multi-hop RAG
- Query routing
- Agentic RAG
RAG Evaluation Metrics:
- Fluency: how well the generated text flows and is easy to read
- Perceived Utility: how useful the generated text is to the user
- Citation recall: how well the generated text cites relevant sources
- Citation Precision: how accurately the generated text cites relevant sources
- Faithfulness: how accurate the generated text is
- Answer Relevance: how relevant the generated text is to the query
Chapter 9: Multimodal Large Language Models
A model that can process text and images is a multimodal model.
Vision Transformer (ViT) is a model that uses the Transformer architecture to process images.
ViT works by breaking an image into patches and then treating each patch as a token.
Multimodal embeddings can be used to represent both text and images in the same vector space.
CLIP is a model that can process both text and images.
How CLIP Training works:
- Text and images are passed through separate encoders to generate embeddings
- The similarity between sentence and image embeddings is calculated using cosine similarity
- The text and image embeddings are trained to maximize the similarity between matching pairs and minimize the similarity between non-matching pairs
Creating a multimodal model requires a lot of power and data. One option is to use pre-trained models.
The Querying Transformer (Q-Transformer) is a model that can process both text and images.
Q-Transformer trains in two stages, one for each modality.
- representation learning is applied for vision and language together
- representations converted to soft prompts for a generative model
Then Q-Transformer is trained on:
- Image-text contrastive learning
- Image-text matching
- Image-grounded text generation
Use cases:
- Image captioning
- Multi-modal chat-based prompting
Chapter 10: Creating Text Embedding Models
Text Embedding models are the core of natural language processing applications.
Embedding Models
Unstructured text data => hard to process
convert text data => numerical vectors => easier to process, usable
semantic nature of text => similar meaning => similar vectors
What is contrastive learning?
Aims to teach models to differentiate between similar and dissimilar pairs of data points.
Ex. Why is this a cat and not a dog?
SBERT: Sentence-BERT is a modification of the BERT network that uses siamese and triplet network structures to derive semantically meaningful sentence embeddings.
Sentence transformers architecture uses a siamese network to generate sentence embeddings.
Creating an Embedding Model
- Generate constrastive examples
- Train the model
- Evaluate the model
Generating Contrastive Examples
Start with a premise and generate positive and negative examples.
Use GLUE benchmark datasets to generate contrastive examples.
Training the Model
- define an evaluator
- use Semantic Textual Similarity Benchmark (STSB)
- use the evaluator to get performance
For more in-depth testing, consider MTEB benchmark.
Use cosine similarity loss function to train the model.
Fine-tuning an embedding model
Supervised is the most straight forward way to fine-tune an embedding model.
Unsupervised approach: Transfomer-Based Sequential Denoising Auo-Encoder (TSDAE)
- Add noise to the input text
- Train the model to reconstruct the original text from the noisy input
- Use the trained model to generate embeddings for new text data
Chapter 11: Fine-Tuning Representation Models for Classification
Supervised Classification
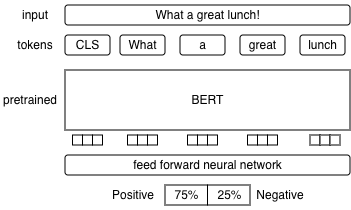
BERT & Feed-Forward Neural Network learn from one another during fine-tuning.
Few-Shot Classification
When labeled data is scarce, few-shot classification can be used to fine-tune a representation model for classification.
SetFit is a framework for few-shot classification that uses contrastive learning to fine-tune a representation model.
Continued Pre-training with Masked Language Modeling (MLM)
Continued pre-training with MLM can be used to adapt a representation model to a specific domain or task.
- Pretraining from scratch
- Continued pre-training from a pre-trained model
- Fine-tuning for a specific task
Named Entity Recognition (NER)
Named Entity Recognition (NER) is the task of identifying and classifying named entities in text.
Chapter 12: Fine-Tuning Generation Models
Three LLM Training Steps: Pretraining, Supervised, Fine-tuning, and Preference Tuning
Steps to creating a high quality LLM:
- Language Modeling Pre-train on one or more massive text datasets => produces a base model
- Fine-Tuning 1 (Supervised Fine-Tuning or SFT) Aims to predict the next token based on an input that has additional labels.
- Fine-Tuning 2 (Preference tuning) Final step to improve quality of model, align with AI Safety or human preferences.
Untrained -> Base -> Instruction Fine-Tuned -> Preference Tuned
Taxonomy
- Accuracy: A metric used to evaluate the performance of classification models, measuring the proportion of correct predictions.
- Attention: A mechanism that allows models to focus on specific parts of the input sequence, improving context understanding.
- Autoregressive Models: Models that generate text by predicting the next token in a sequence based on the previous tokens.
- Bag of Words (BoW): A simple representation of text that ignores grammar and word order but keeps track of word frequency.
- BERT (Bidirectional Encoder Representations from Transformers): A pre-trained model that uses a Transformer architecture to understand the context of words in a sentence.
- Byte Tokens: A tokenization scheme that represents text as a sequence of bytes, allowing for a more compact representation.
- Character Tokens: A tokenization scheme where each token represents a single character, useful for languages with complex morphology.
- Context Size: The number of tokens the model can consider at once when generating text, affecting its ability to maintain coherence.
- Embeddings: Numerical representations of words or tokens that capture their semantic meaning and relationships.
- F1 Score: A metric that combines precision and recall to evaluate the performance of classification models.
- Feed-Forward Neural Network: A type of neural network where connections between nodes do not form cycles, used in Transformer blocks.
- Flash Attention: An efficient attention mechanism that reduces memory usage and speeds up computation in LLMs.
- GPT (Generative Pre-trained Transformer): A type of LLM that is pre-trained on a large corpus of text and can generate coherent text based on a given prompt.
- Greedy Decoding: A text generation strategy where the model selects the token with the highest probability at each step.
- Grouped Query Attention (GQA): An attention mechanism that uses a single set of keys and values for multiple queries, improving efficiency.
- Inverse Document Frequency (IDF): is a measure of how important a word is to a document in a collection of documents.
- Large Language Models (LLMs): A type of AI model that is trained on large datasets to understand and generate human language.
- LM Head: The final layer of an LLM that generates the output tokens based on the processed input.
- Mean Average Precision (MAP): A metric used to evaluate the performance of information retrieval systems, measuring the average precision across multiple queries.
- Multi-Head Attention: An attention mechanism that allows the model to focus on different parts of the input sequence simultaneously.
- Output vectors: The numerical representations of the output tokens generated by the LLM.
- Parallel Processing: The ability to process multiple input tokens simultaneously, improving efficiency.
- Precision: The numerical accuracy of the computations performed by the model, affecting its performance and resource usage.
- Recall: A metric used to evaluate the performance of classification models, measuring the ability to identify all relevant instances.
- Self-Attention: A mechanism that allows the model to weigh the importance of different tokens in the input sequence when generating text.
- Sparse Attention: An efficient attention mechanism that uses fewer input tokens as context for self-attention, reducing computational complexity.
- Subword Tokens: A tokenization scheme where tokens can represent parts of words, allowing for better handling of rare or unknown words.
- T5 model: Text-To-Text Transfer Transformer, a model that converts all NLP tasks into a text-to-text format.
- Temperature: A parameter that controls the randomness of the model’s output, with higher values leading to more diverse text.
- Tokenization: The process of breaking down text into smaller units (tokens) for processing by LLMs.
- Token Embedding: The process of converting tokens into numerical vectors that capture their semantic meaning.
- Token Probabilities: The likelihood of each token in the vocabulary being the next token in a sequence, used for text generation.
- Top-p Sampling (Nucleus Sampling): A text generation strategy that selects tokens from the smallest set whose cumulative probability exceeds a threshold p, allowing for more diverse outputs.
- Transformer: A neural network architecture that uses self-attention mechanisms to process sequences of data, widely used in LLMs.
- Transformer Blocks: The building blocks of the Transformer architecture, consisting of layers of attention and feed-forward neural networks.
- Trained Transformer LLMs: LLMs that have been trained on large datasets using the Transformer architecture, enabling them to understand and generate human language effectively.
- Word Tokens: A tokenization scheme where each token represents a whole word.
- word2vec: A technique that uses neural networks to learn word embeddings, capturing semantic relationships between words.
References:
- Speech and Language Processing
- Attention Is All You Need
- Generating Long Sequences with Sparse Transformers
- Fast Transformer Decoding: One Write-Head is All You Need
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- FlashAttention-2:Faster Attention with Better Parallelism and Work Partitioning
- The Illustrated Transformer
- On Layer Normalization in the Transformer Architecture
- Root Mean Square Layer Normalization
- GLU Variants Improve Transformer
- RoFormer: Enhanced Transformer with Rotary Position Embedding
- Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance
- Introducing packed bert for 2x faster training in natural language processing
- A Survey of Transformers
- Transformers in Vision: A Survey
- A Survey on Vision Transformer
- Open X-Embodiment: Robotic Learning Datasets and RT-X Models
- Transformers in Time Series: A Survey
- HuggingFace Datasets
- HuggingFace Cornell Rotten Tomatoes
- Scaling Instruction-Finetuned Language Models
- ArXiv
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Understanding searches better than ever before
- Bing delivers its largest improvement in search experience using Azure GPUs
- Introduction to Information Retrieval
- Evaluation in information retrieval
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- UKPLab Sentence Transformers
- https://gluebenchmark.com/
