Book Notes: AI and Machine Learning for Coders - A Programmer's Guide to Artificial Intelligence
Overview
This post contains my notes on the book AI and Machine Learning for Coders - A Programmer’s Guide to Artificial Intelligence by Laurence Moroney[^1]. The book is a practical guide to building AI and machine learning applications using TensorFlow and Keras. It covers the basics of machine learning, deep learning, and neural networks, and provides hands-on examples of how to build and deploy AI applications.
You can find the book on Amazon
I’ll be adding my notes to this post as I read through the book. The notes will be organized by chapter and will include key concepts, code examples, and any additional insights I find useful.
Chapter 1: Introduction to tensorflow
In chapter 1 you’ll learn about the limitations of traditional programming and get some initial insight into Machine Learning. You’ll learn how to install tensorflow, in my case on a M2 Mac.
I searched around a little to see what common issues occurred for mac installations and came across a handy blog that covered different tensorflow installation options and included a handy script to verify tensorflow was indeed using my gpu. After a brief hiccup I added the following packages to my installation, re-ran the script and was on my way.
pip install tensorflow
pip install tensorflow-macos tensorflow-metal
At the end of this chapter you’ll build and train your first model, a simple linear regression model that predicts the output of a linear equation.
Note: Using the coding samples located in GitHub will make following along really easy. https://github.com/lmoroney/tfbook
Chapter 2: Introduction to Computer Vision
Using the Fashion MNIST dataset, chapter 2 introduces the reader to Neural Network design. Using a real, but simiple dataset, you’ll learn how to build a neural network that can classify images of clothing.
Chapter 3: Convolutional Neural Networks
In chapter three, you’ll explore Convolutional Neural Networks using images of humans and horses. You’ll use training and validation data to build up a model as well as learn about image augmentation to broaden the data and reduce overspecialization. Additional concepts introduced include Transferred Learning, Multiclass Classification, and Dropout Regularization.
Chapter 4: Using Public Datasets with TensorFlow Datasets
Using the TensorFlow Datasets library, chapter 4 introduces the reader to ETL which is a core pattern for training data. The chapter covers a practical example as well as how to use parallelization ETL to speed up the process.
Chapter 5: Natural Language Processing
Chapter 5 introduces the reader to tokenization, taking text and breaking it down into smaller units (tokens) for processing. It covers basics like Turning sentences into tokens, padding sequences, as well as more advanced techniques like removing stop words, and text cleaning.
The examples in this chapter use the IMDB, emotional sentiment, and scarcasim classification datasets as examples for building datasets from html like data, csv files, and json.
Chapter 6: Making Sentiment Programmable Using Embeddings
Chapter 6 uses a Sarcasm dataset to introduce the reader to word embeddings. Words are given a numerical representation of positive numbers that represent Sarcasm and negative numbers that represent realistic statements. Sentences could then be represented as a series of these numbers and evaluated for a Sarcasm score.
The example in this chapter begins to analyze accuracy and loss against the training and validation datasets. This can help identify overfitting, which is when the model becomes overspecialized to the training data.
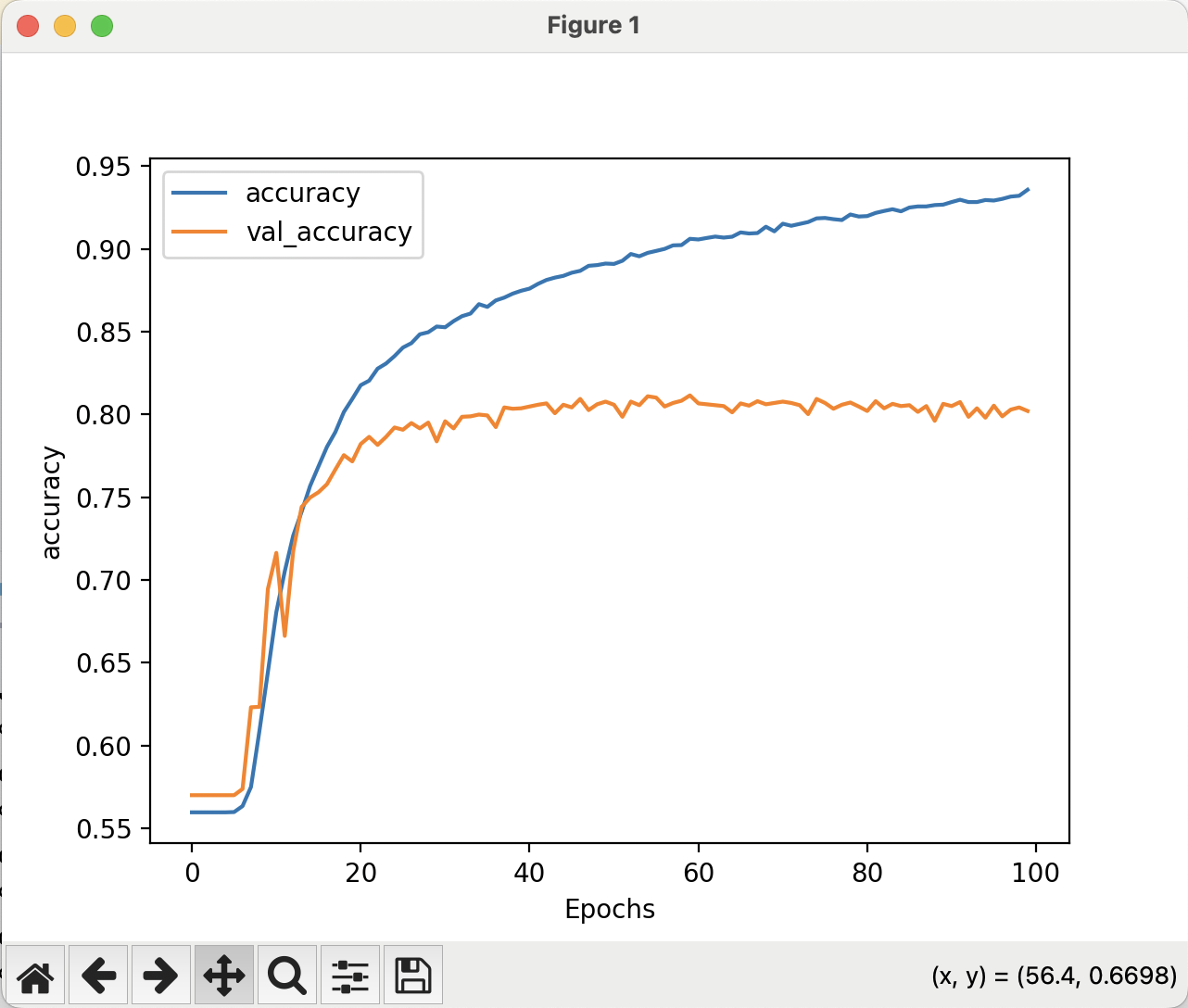
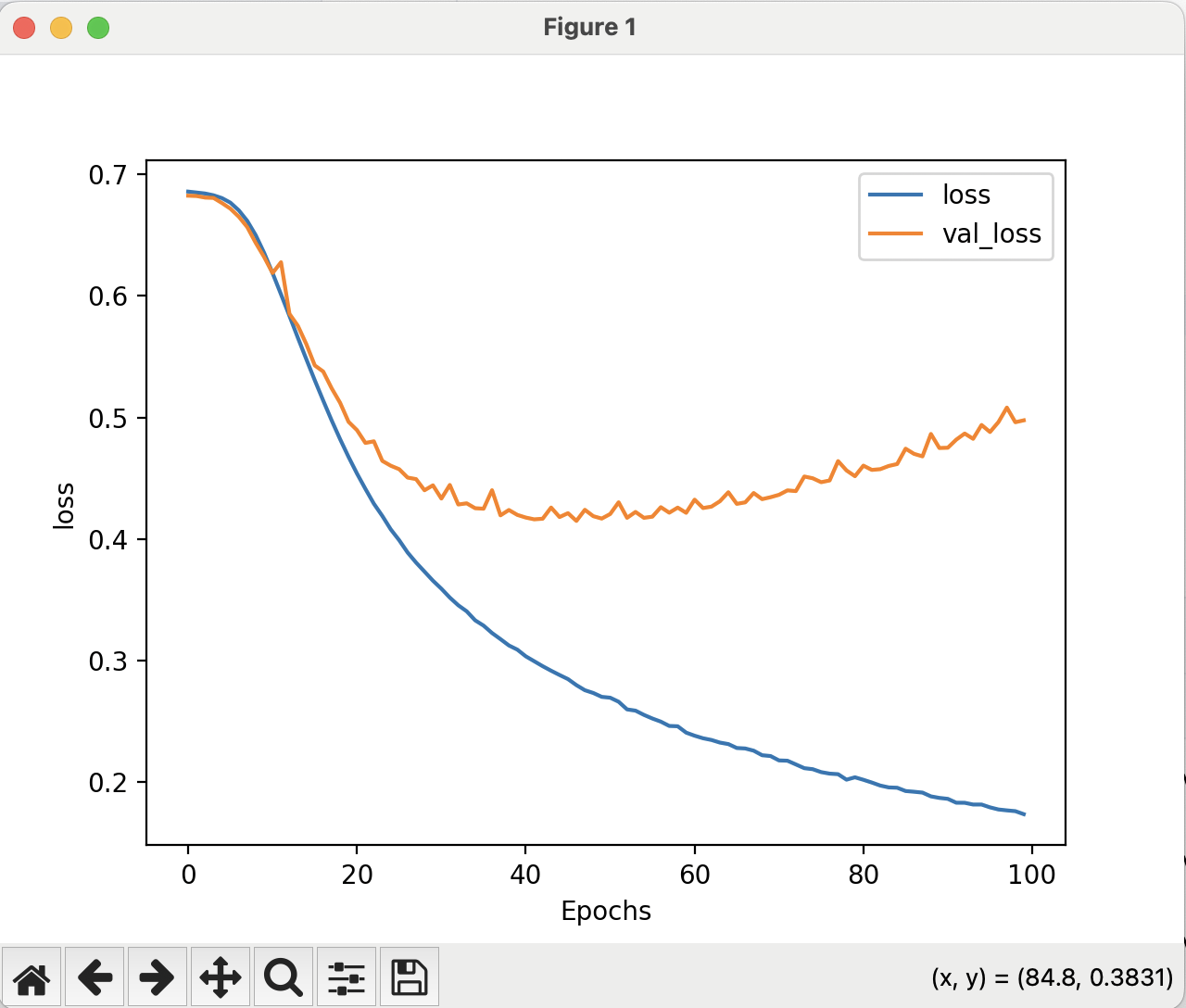
The example goes on to cover various techniques to improve the model. These include:
- Adjusting the learning rate
- Adjusting the vocabulary size
- Adjusting the embedding dimension
When these techniques are applied, finer tuning of the model can be achieved by:
- Using dropout
- Using regularization
Chapter 7: Recurrent Neural Networks for Natural Language Processing
Chapter 7 introduces Recurrent Neural Networks (RNNs) and how they can be used for Natural Language Processing tasks.
They provide a diagram of a recurrent neuron which shows how a recurrent neuron is architected.
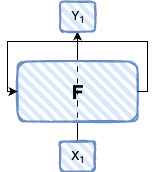
Long Short-Term Memory (LSTM) is a type of RNN that is capable of learning long-term dependencies.
Bidirectional LSTMs are a type of LSTM that can process data in both directions, which can be useful for tasks like sentiment analysis where context from both the past and future can be important.
The exercise in this chapter reuses the exercise from chapter 6 and introduces stacked LSTMs.
Overtraining occurs in the example, so optimization techniques are applied to improve the model. These include:
- Adjust the learning rate
- Using dropout in the LSTM layers
A second example in this chapter uses pretrained embeddings, the GloVe set. In this second example, after the model is downloaded, an exercise to determine how many of the words in the corpus are in the GloVe vocabulary is performed.
Chapter 8: Using TensorFlow to Create Text
This chapter starts out with an example of tokenizing text and creating a word index. Then a model is built so that it can be trained.
With a trained model it can be used to predict the next word in a seqence. We can then use seed text to generate a token and test the model. We can then repeat this process to generate mode text with alternate seed text.
Using the same process we can use a differet, larger dataset to generate more complex text. The example adjusts the model slightly by adding an additional LSTM layer and increasing the number of epochs.
Chapter 9: Understanding Sequence and Time Series Data
Common attributes of time series data include:
- Trend
- Seasonality
- Autocorrelation
- Noise
Techniques for predicting time series data include:
- Naive Prediction to create a baseline
Measuring Prediction accuracy:
- Mean Absolute Error (MAE)
- Mean Squared Error (MSE)
Less Naive: Using Moving Averages
Chapter 10: Creating ML Models to Predict Seqeuences
Windowed datasets can be used to emulate a time series dataset. The example in this chapter uses a window size of 5 to predict the next value in the sequence.
It goes through the process of creating a windowed version of time series data, then building and training a model.
Tuning the model can be done through the use of Keras Tuner.
Chapter 11: Using Convolutional and Recurrent Methods for Sequence Models
This chapter continues the work from chapter 10 and introduces the use of Convolutional Neural Networks (CNNs) for sequence modeling.
It goes over the parameters of the Conv1D layer and how they can be used in the model.
It then goes on to use NASA weather data and using RNNs for seqence modeling and some tuning approaches.
This includes:
- Using Other recurrent methods, like gated recurrent units (GRU) and long short-term memory layers (LSTM)
- Using Dropout
- Using bidirectional RNNs
Chapter 12: An introduction to tensorflow lite
TensorFlow lite is a mobile version of TensorFlow.
The book walks through the process of converting a model to TensorFlow lite and then using it.
Chapter 13: Using TensorFlow Lite in Android Apps
This chapter walks through the process of using TensorFlow lite in an Android app.
I didn’t spend much time on this chapter as I don’t do Android development.
Chapter 14: Using TensorFlow Lite in iOS Apps
This chapter walks through the process of using TensorFlow lite in an iOS app.
I didn’t spend much time on this chapter as I don’t do iOS development.
Chapter 15: An Introduction to TensorFlow.js
This chapter walks through the process of using TensorFlow.js and how you can train models in the browser.
I didn’t spend much time on this chapter.
Chapter 16: Coding Techniques for Computer vision in TensorFlow.js
This chapter was another chapter that spend time on brower-based image classification.
I didn’t spend much time on this chapter.
Chapter 17: Reusing and Converting Python Models to JavaScript
This chapter walks through the process of converting python-created models and converting them to TensorFlow.js.
I didn’t spend much time on this chapter.
Chapter 18: Tranfer Learning in JavaScript
This chapter walks through the process of using transfer learning in TensorFlow.js.
I didn’t spend much time on this chapter.
Chapter 19: Deployment with TensorFlow Serving
This chapter walks through the process of using TensorFlow Serving to deploy models.
I didn’t spend much time on this chapter.
Chapter 20: AI Ethics, Fairness, and Privacy
This chapter covers some of the ethical considerations when using AI and machine learning.
- Fairness
- Facets
- Federated Learning
Taxonomy
- Autocorrelation: The correlation of a signal with a delayed copy of itself as a function of delay.
- Convolution: Mathematical filter that works on the pixels of an image.
- Dropout: A regularization technique that randomly sets a fraction of input units to 0 at each update during training time, which helps prevent overfitting.
- Embedding Dimension: The size of the vector representation of each word in the vocabulary.
- Learning Rate: A hyperparameter that controls how much to change the model in response to the estimated error each time the model weights are updated.
- Long Short-Term Memory (LSTM): A type of recurrent neural network (RNN) architecture that is capable of learning long-term dependencies.
- Natural Language Processing (NLP): A field of AI that focuses on the interaction between computers and humans through natural language.
- Noise: Random variation in data that does not contain useful information.
- Out of Vocabulary (OOV): Words that are not present in the training vocabulary.
- Overfitting: When the model becomes overspecialized to the training data.
- Padding: Adding zeros to the beginning or end of a sequence to make it a fixed length.
- Regularization: Techniques used to prevent overfitting by adding a penalty to the loss function based on the complexity of the model.
- Seasonality: A pattern that repeats at regular intervals in the data.
- Stop Words: Common words that are often removed from text data to reduce noise and improve model performance.
- Tokenization: The process of breaking down text into smaller units (tokens) for processing.
- Transfer Learning: Taking layers from another architecture.
- Trend: A long-term increase or decrease in the data.
- Vocabulary Size: The number of unique words in the training dataset.
